哈希表 高效数据存储与快速检索的基石
在当今信息爆炸的时代,数据处理的速度和效率直接决定了系统的性能与用户体验。在众多数据结构中,哈希表凭借其卓越的存储与检索能力,已成为支撑现代计算基础设施的核心组件之一。它不仅是编程语言内置集合类型(如Python的字典、Java的HashMap)的实现基础,更是数据库索引、缓存系统、编译器符号表乃至网络安全协议中不可或缺的一环。
一、 核心原理:从键到值的直接通路
哈希表的核心思想在于“直接访问”。它通过一个称为“哈希函数”的算法,将任意大小的输入(键,Key)映射到一个固定大小的数值(哈希值,Hash Value)。这个哈希值通常作为数组的索引,从而可以直接定位到存储对应值(Value)的“桶”(Bucket)。理想情况下,这个操作的时间复杂度为O(1),即常数时间,与数据量大小无关,这奠定了其高效检索的基石。
二、 高效存储:空间与时间的精妙平衡
哈希表的高效不仅体现在检索上,也体现在存储管理。
- 负载因子与动态扩容:哈希表维护一个“负载因子”(已存储键值对数量与桶总数之比)。当负载因子超过某个阈值(通常为0.75),发生哈希冲突的概率会显著增加,性能下降。此时,哈希表会执行“扩容”(Rehashing),创建一个更大的桶数组,并将所有现有条目重新哈希并放入新数组。这个过程虽耗时,但分摊到多次插入操作中,平均时间复杂度仍接近O(1)。
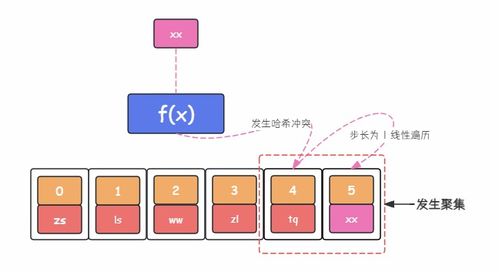
- 冲突解决策略:当两个不同的键经过哈希函数计算得到相同的索引时,就发生了“哈希冲突”。高效的冲突解决机制是保障性能的关键。主要方法有:
- 链地址法:每个桶指向一个链表(或树结构),所有哈希到同一索引的条目依次存入该链表。这种方法简单有效,被广泛采用。
- 开放定址法:当发生冲突时,按照某种探测序列(如线性探测、二次探测)在数组中寻找下一个空闲桶。这种方法数据存储在数组中,对缓存更友好,但在高负载时性能衰减明显。
三、 快速检索:近乎即时的数据查找
哈希表的查找过程是其设计目的的完美体现:
1. 对给定的键计算哈希值。
2. 通过哈希值对数组长度取模,得到目标桶索引。
3. 在目标桶中(可能是链表或通过探测找到的位置)比对键本身(因为哈希值可能相同),找到精确匹配的条目并返回其值。
只要哈希函数分布均匀,冲突较少,这个过程就极其迅速,使得哈希表在需要频繁进行“存在性检查”和“值获取”的场景中无可替代,例如用户会话管理、字典查询、唯一性过滤等。
四、 作为数据处理和存储的支持服务
哈希表的特性使其成为更大型数据处理和存储系统的关键支撑服务:
- 数据库索引:许多数据库的哈希索引,允许对等值查询进行极速定位,虽然它不支持范围查询。
- 缓存系统:Memcached、Redis等缓存中间件,其核心就是将键值数据存储在内存哈希结构中,以实现微秒级的响应。
- 编译器与解释器:用于快速查找和管理变量名、函数名等符号及其属性。
- 网络与安全:路由表快速查找、数字指纹(如MD5、SHA系列)用于数据完整性校验,其本质也是哈希技术的应用。
- 分布式系统:一致性哈希算法用于在分布式缓存或数据库中高效、均匀地分配数据,减少节点增减时的数据迁移量。
五、 权衡与优化
没有一种数据结构是完美的,哈希表在追求速度的同时也需权衡:
- 空间开销:为了保持低负载因子以减少冲突,哈希表通常会预留比实际数据更多的空间(数组有空闲)。
- 无序性:标准哈希表不维护元素的插入顺序(但如Java的LinkedHashMap等变体可以)。
- 哈希函数质量:一个糟糕的哈希函数会导致大量冲突,使性能退化为O(n)。因此,设计或选择能产生良好均匀分布的哈希函数至关重要。
###
哈希表以其简洁而强大的设计理念,在计算机科学的舞台上扮演着“加速器”的角色。它将看似耗时的查找问题转化为近乎即时的地址计算问题,是算法设计中“以空间换时间”策略的杰出典范。从单机应用到大规模分布式系统,哈希表持续为高效的数据处理与存储提供着最基础、最核心的支持服务,是现代计算生态中名副其实的无声基石。理解并善用哈希表,是每一位软件工程师和系统架构师构建高性能应用的必备技能。
如若转载,请注明出处:http://www.soooy44.com/product/1.html
更新时间:2026-05-28 00:33:17